06.30
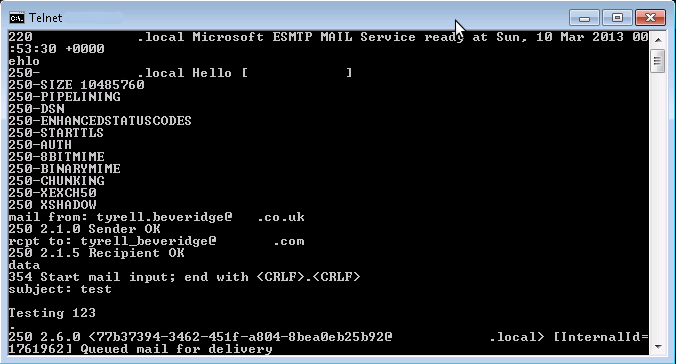
I ran into an error compiling the Nagios NRPE plugins on my Arch linux raspberry pi as follows:
In file included from localcharset.c:28:0:
./stdio.h:456:1: error: ‘gets’ undeclared here (not in a function)
make[4]: *** [localcharset.o] Error 1
make[4]: Leaving directory `/root/nagios-plugins-1.4.16/gl'
make[3]: *** [all-recursive] Error 1
make[3]: Leaving directory `/root/nagios-plugins-1.4.16/gl'
make[2]: *** [all] Error 2
make[2]: Leaving directory `/root/nagios-plugins-1.4.16/gl'
make[1]: *** [all-recursive] Error 1
make[1]: Leaving directory `/root/nagios-plugins-1.4.16'
make: *** [all] Error 2
A quick Google search brought me to the following page with details of the patch to fix the error:
http://bugzilla.redhat.com/show_bug.cgi?id=835621#c6
Edit the nagios-plugins-1.4.16/gl/stdio.in.h file and search for the following lines:
#undef gets
_GL_WARN_ON_USE (gets, "gets is a security hole - use fgets instead");
Add the following if statement as follows:
#if defined gets
#undef gets
_GL_WARN_ON_USE (gets, "gets is a security hole - use fgets instead");
#endif
Your plugins should now compile successfully and you can continue your install as normal. Steps for a normal install are detailed below:
1 pacman -S base-devel
2 tar -xvf nagios-plugins-1.4.16.tar.gz
3 cd nagios-plugins-1.4.16
4 ./configure
5 make
6 make install
7 chown nagios.nagios /usr/local/nagios
8 chown -R nagios.nagios /usr/local/nagios/libexec
9 tar -xvf nrpe-2.14.tar.gz
10 cd nrpe-2.14
11 ./configure
12 make all
13 make install-plugin
14 make install-daemon
15 make install-daemon-config
16 make install-xinetd
17 nano /etc/xinetd.d/nrpe
Add Server IP Address
18 nano /etc/services
Add nrpe 5666/tcp
19 pacman -S xinetd
20 systemctl start xinetd
21 netstat | grep 5666
22 /usr/local/nagios/libexec/check_nrpe -H localhost
23 systemctl enable xinetd
24 nano /usr/local/nagios/etc/nrpe.cfg
25 systemctl restart xinetd








 SSL certificates are used to verify your identity as well as encrypt traffic between two hosts using
SSL certificates are used to verify your identity as well as encrypt traffic between two hosts using